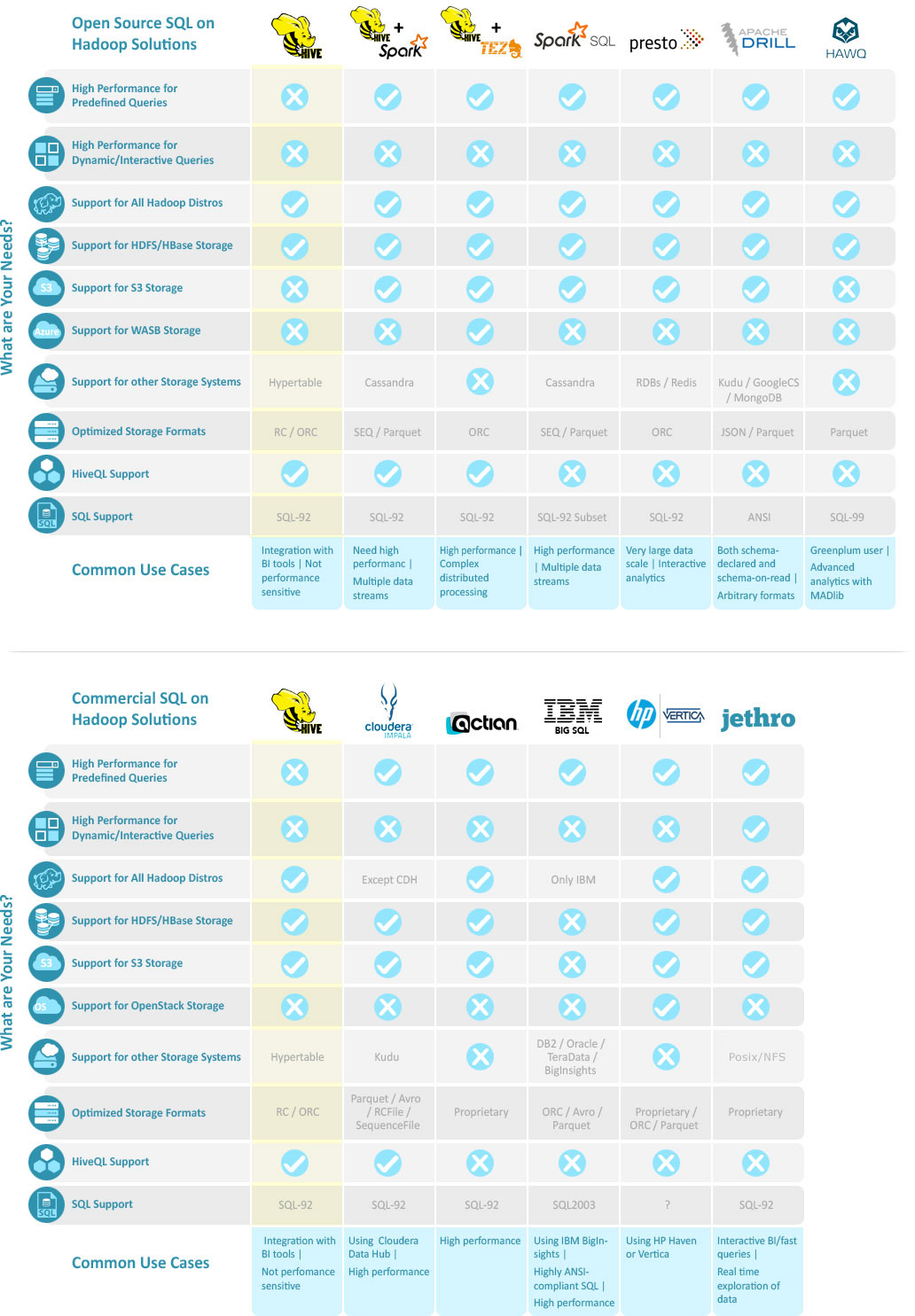
Hadoop Hive and 11 SQL-on-Hadoop Alternatives
Hive and SQL-on-Hadoop
Hive was arguably the first SQL engine on Hadoop – it was designed to receive SQL queries from any source and process them directly against data stored in Hadoop. This helped bridge the gap between the existing skill sets of data engineers and the new Hadoop platform – it was possible to continue working with SQL queries, but actually querying big data on Hadoop on the back end.
Over the years a variety of new SQL on Hadoop engines have been introduced – variants of Hive (Hive on Spark and Hive on Tez), other tools developed natively in the Hadoop platform (e.g. Impala, Drill), and yet others which are general purpose tools adapted to work in Hadoop (e.g. HAWQ, Actian). All of them have superior performance and features compared to the original Hive.
In this page we’ll help you wrap your mind around the SQL on Hadoop landscape and compare 11 Hive alternatives that might be relevant for your needs.
The Big Roundup: Hadoop Hive and 11 Alternatives
Understanding SQL-on-Hadoop Performance
Performance is a central issue for SQL on Hadoop. The original Hive which relied on Hadoop’s MapReduce suffered from poor performance, making it mainly applicable for batch queries or ETL scenarios and less so for fast/interactive queries. More modern tools, including the later versions of Hive which run on Tez and Spark, have substantially improved query performance and latency.
OPTIMIZED DATA FORMATS
The traditional way to improve the performance of SQL on Hadoop is to use an optimized data format. Raw data typically arrives as Text or JSON files, and converting it to a columnar binary format provides a significant performance boost. Popular open columnar formats are ORC and Parquet, used by many of the native Hadoop engines. Kudu, a new data format (and file system) was recently announced and supported by Impala and Drill, which performs even better.
A newer generation of commercial tools which are focused on high performance use their internal proprietary data formats for columnar storage – two examples are Actian and Jethro. These data formats are even faster than the generic formats like ORC and Parquet; the downside is that you’ll need to convert your data to the vendor’s proprietary format.
Besides optimized data formats, some of the SQL on Hadoop tools employ other techniques to boost performance – SQL query optimization, multi-threaded processing, and vectorization of queries.
INDEXING – ORDER-OF-MAGNITUDE PERFORMANCE BOOST
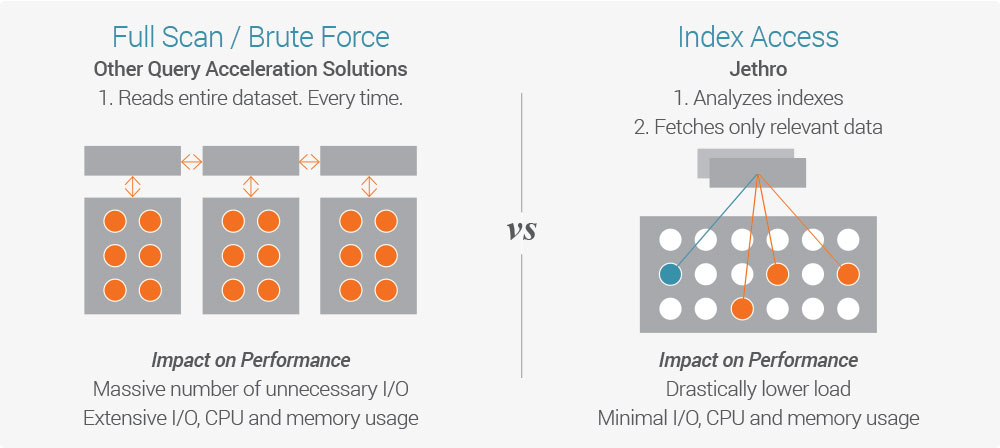
A new innovation in SQL on Hadoop performance was introduced by Jethro (that’s us). Jethro’s big data platform fully indexes every single column of the dataset on Hadoop HDFS. It leverages these indexes to access only the data necessary for a query, instead of performing a full scan like all other SQL on Hadoop tools.
Because data is accessed directly instead of waiting for a full scan, responses to queries are faster by an order of magnitude, enabling real-time response to queries and interactive exploration of data.
Queries can leverage multiple indexes for better performance – the more a user drills down, the faster the query runs.
Non-index-based tools can also provide fast query response, but only given a physical pre-organization of the data (sorting, partitioning). This pre-organization is done for specific queries or scenarios (e.g. queries by date or geographical region) – queries using a different structure will be dramatically slower.
Index-Based Architecture is the Best SQL-on-Hadoop for Fast Interactive Queries
There are many great tools out there for SQL on Hadoop, but only Jethro enables real time response to queries while querying the entire big data set–even as the user drills down and explores the data set and changes their query parameters.
Jethro’s unique index-based architecture enables direct access to the data relevant to the user’s query without requiring a full scan, which is an order of magnitude faster. Other tools can provide real-time access to pre-defined types of queries, e.g. based on time or geographical region, but if the user tries to query using other parameters, there will be a long wait for a full scan of the data.