HP Vertica is a column-oriented big data platform that focuses on SQL compatibility, support for both structured and semi-structured data sources, including Hadoop, and high performance. However, because Vertica is based on a Massively Parallel Processing (MPP) architecture, in many scenarios it will not be able to provide the real time query performance that users expect. We explain this problem later in this post, and suggest a solution.
Vertica - Hadoop Analytics for the Enterprise
HP Vertica performs advanced analytics on any Hadoop distribution, and promises to get an organization’s Hadoop analytics “out of the sandbox”. It offers a mature SQL engine which is robust and concurrent regardless of the volumes of data in the Hadoop cluster.
Some of HP Vertica’s key capabilities are:
- Full ANSI SQL support
- Support for all Hadoop distributions
- Ability to install Vertica directly on Hadoop nodes without helper nodes
- Support for numerous data formats including Parquet, ORC and JSON
- A data exploration mode which allows you to prepare data for production, and then load it into the high performance modules of Vertica
See more details on using Vertica with Hadoop from HP.
Vertica and the MPP Architecture
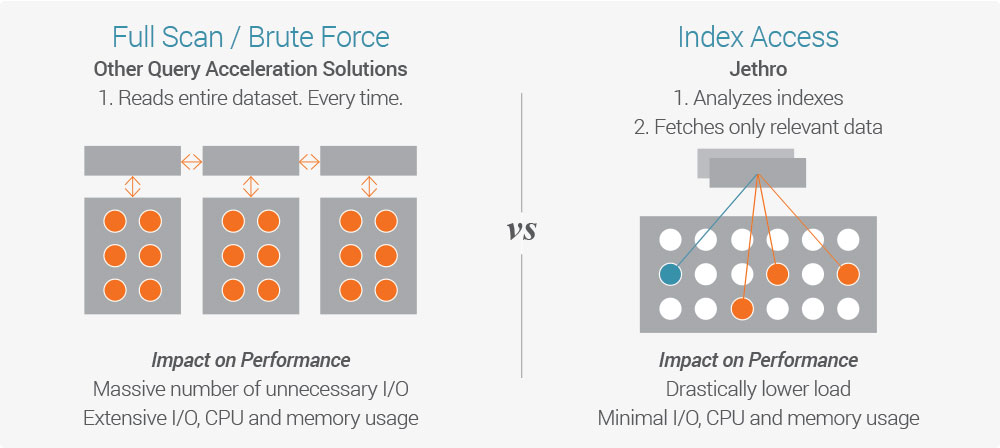
Vertica is based on an MPP (Massively Parallel Processing) architecture. This means that each time a query is made, the entire dataset is scanned for the answer - a “full scan”. This places inherent limits on performance with large data sets, despite Vertica’s in-memory processing and optimized data formats, which provide a large performance improvement.
The more a user drills down and applies additional filters on the data, the more full scans are needed to assemble the relevant data to answer the query. This creates a massive number of unnecessary I/O operations and high CPU and memory usage. In the end this translates into high latency for complex user queries.
For simpler user queries, or queries that were known in advance, HP Vertica can provide excellent performance. This is dependent on pre-structuring of the data set to allow easy access for the specific query (e.g. the data can be re-organized by date, and then date-based queries will run very fast). But as soon as queries start getting complex or users have a need to change their query fields frequently, multiple full scans of the data may be needed, and query latency degrades.
Index-Based Processing for Complex User Queries
An index-access architecture is the most flexible solution for directly querying big data sources. HP Vertica and other engines rely on MPP (massively parallel processing database) architectures that fully-scan the entire database with every query. By contrast, drill-down, index-access architecture removes the need for limiting extracts or cubes and allows you to query your data and drill-down any way you’d like, at interactive speed.
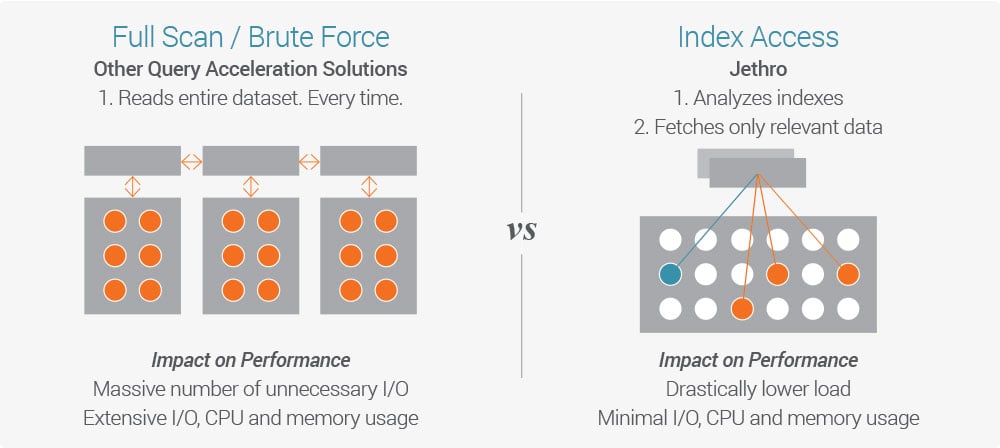
Jethro is an index-access SQL acceleration engine that was built for the unique scenario of flexible user queries on large data sets. Instead of fully scanning the data (MPP), like Vertica and all other SQL on Hadoop tools, Jethro indexes every single column of the dataset on Hadoop HDFS.
Jethro leverages these indexes to surgically access only the data necessary for a query instead of waiting for a full scan, resulting in query response times that are faster by an order of magnitude. This enables a true interactive response to user queries. Queries can leverage multiple indexes for better performance - the more a user drills down, the faster the query runs.
We ran a benchmark putting Jethro head to head with Cloudera Impala, another high performance SQL on Hadoop engine based on an an MPP architecture, like Vertica. The benchmark tested how long each system takes to refresh a Tableau visualization of a dataset with 2.8 billion rows stored in Hadoop.
Impala (based on MPP architecture like Vertica) took over 1.5 minutes to refresh the Tableau dashboard, while Jethro (index-based) took only 6 seconds on average. This enables truly interactive processing of big data.

