The brand new Jethro 1.2.0 release packs another powerful performance feature called Join Indexes. Join indexes accelerate performance of join queries with where clause on a dimension value. Combined with Jethro star transformation optimization, join indexes ensure that Jethro uses the most optimized index-based plan whenever possible for join queries.
Index based join optimization - typical scenario walk through
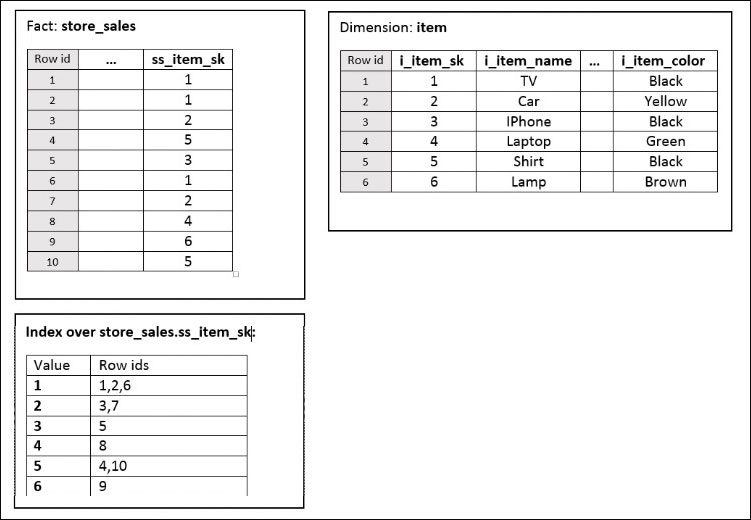
To explain how index-based join optimization works in Jethro, we will follow this example: a fact table store_sales is joined with item dimension via item sk columns (ss_item_sk=i_item_sk). Each item has name (i_item_name) attribute and color (i_item_color) attribute. While item name attribute is unique (different value for each item) item color attribute have repeated value, where multiple item may have the same color.
See following figure to illustrate the example:
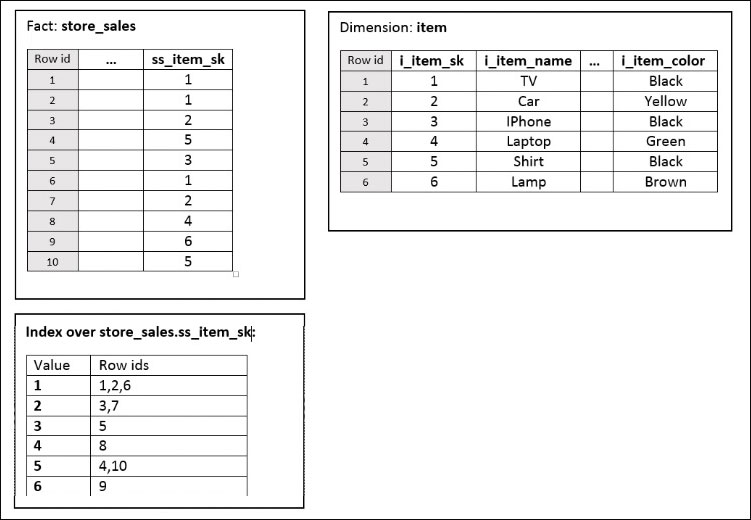 Figure 1: Example Schema
Figure 1: Example Schema
A common analysis request could be: aggregate some measures from the fact with specific related item color(s). For this example we will use this SQL query:
SELECT SUM(SS_SALE_PRICE)
FROM STORE_SALES JOIN ITEM ON SS_ITEM_SK=I_ITEM_SK
WHERE I_ITEM_COLOR=’BLACK’;
Any non-index based query engine would execute this join by fully scanning all of the relevant columns from the fact table and joining each fact tuple with the dimension. With Jethro indexes a much more optimized plan is used: this query is rewritten so that IN clause replaces the where on the dimension table. Rewrite SQL would be:
SELECT SUM(SS_SALE_PRICE)
FROM STORE_SALES WHERE
SS_ITEM_SK IN (SELECT I_ITEM_SK FROM ITEM WHERE I_ITEM_COLOR=’BLACK’);
Following this rewrite Jethro now uses the SS_ITEM_SK index to fetch only the fact values matching the where criteria and saving an expensive full-scan of all columns. In addition, the original join may be eliminated (as in the above example) if the join column on the dimension is unique for non-NULL values, thus saving the join calculation costs.
The above rewrite is called star transformation and it is an extremely effective method for Jethro to accelerate queries performance in ratios of X10 to X1000. However, sometimes this is not enough.
Jethro star transformation limitations
Transforming join queries to index based queries provides great performance acceleration but has its own limitation. When the amount of values in the IN list becomes very big performance can degrade as the number of index merges (OR operations) grows. For example - if item color BLACK represent over a 10,000 items the IN subquery returns a huge list of 10,000 i_item_sk values which means 10,000 index merge operations in the fact table. In such scenario Jethro planner may revert to full scan execution to avoid an expensive multi index values merge. To resolve this scenario we will use join indexes.
What is a join index
Join index is an index on a table (fact), based on the values of another table (dimension) column and on a specific join criteria. Typically it is an index on a large fact table based on the values of a dimension attribute. Join index accelerates queries by eliminating both the fetch of the join key from the fact table and the join execution for low cardinality attributes of large dimensions.
A simple way to understand a join index is to envision it as a transparent denormalized index view of the schema. In fact, a join index is implemented as an additional virtual index only column on the fact table that is generated from the results of a join expression between the fact and the dimension.
Let’s include in our example a join index over the item.i_item_color column using join keys store_sales.ss_item_sk and item.i_item_sk:
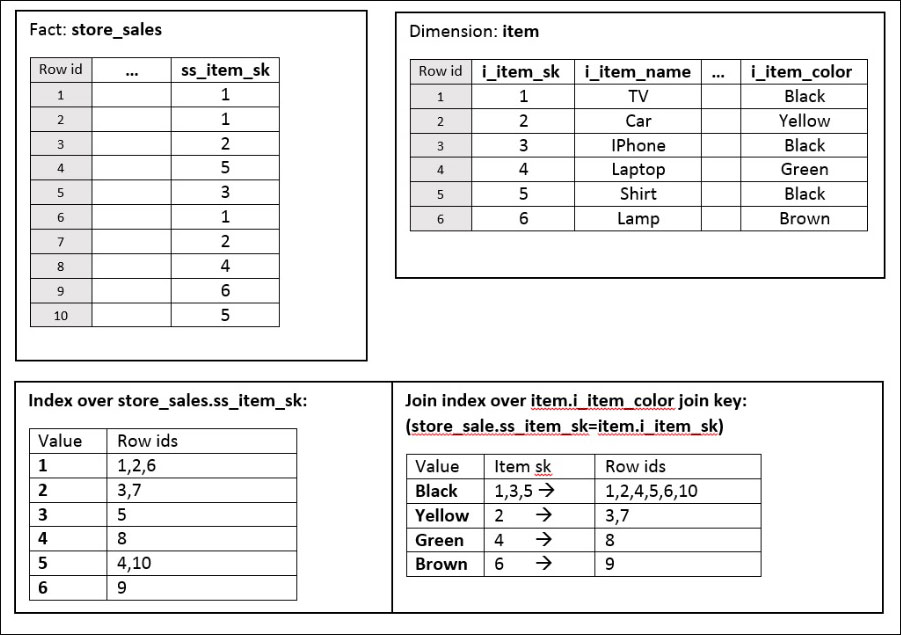 Figure 2: Example Schema with Join Index
Figure 2: Example Schema with Join Index
When the Jethro planner chooses to do star transformation, it checks if a join index exists for the relevant join condition and attribute column. If the join index is found it will be used and the where results are received within a single index access per attribute value.
Typical Join Index Use Case
Join indexes are relevant we have relatively large dimension (few K values or more) and the attribute (the column in the dimension) is low cardinality so that each value in the attribute represent large number of join key values.
Typically a join index is defined if the average ratio between unique dimension attribute and the related join keys value is 1000 or more, but if fact table is large (more than few billion) it is recommended to define join index for attribute with smaller number of related join keys per value.
How to create a join index
A new join index is created using the command CREATE JOIN INDEX. A preliminary constraint requires that the dimension join key will be unique so it must be defined as a PRIMARY KEY.
In our example we will use the following commands:
To define i_item_sk as primary key:
ALTER TABLE item ADD PRIMARY KEY (i_item_sk)
To create join index over item.i_item_color using store_sales.ss_item_sk and item.i_item_sk as join keys:
CREATE JOIN INDEX store_sales_by_item_color_idx
ON store_sales(item.item_color)
FROM store_sales JOIN item ON ss_item_sk = i_item_sk;
Join index maintenance
The great thing about join indexes is that it requires no maintenance by the user. Once defined, a join index is transparently updated following any change in the fact or related dimension data. The related join indexes are updated automatically and are always kept up-to-date whenever new data are appended to the fact or dimension or whenever the fact or dimension is overwritten or truncated.
Join indexes is yet another great performance enhancement tool by Jethro that leverages the power of Jethro indexes to run super fast join queries over normalized schemas.

