A SQL-on-Hadoop Engine that Harnesses the Power of Full Indexing, a Columnar Structure and Intelligent Caching to Achieve Interactive BI Speed on Big Data.
Jethro is a SQL-on-Hadoop engine that accelerates your BI Tool visualizations, such as Tableau, Qlik or Microstrategy, by taking a unique approach to accessing big data on Hadoop. Jethro’s SQL-on-Hadoop engine acts as an acceleration layer and is unobtrusively sandwiched between Hadoop and a BI Tool.
The Fastest SQL-on-Hadoop Engine for BI. Jethro accelerates BI visualizations connected to multi-billion-row tables to perform at interactive speeds.
Fastest SQL-on-Hadoop
EASY TO GET STARTED ON HADOOP
Just install Jethro on one or few dedicated servers, point it to your Hadoop cluster, load some data and start querying. When working with Hadoop, Jethro is safe and easy to implement as it only connects remotely as an HDFS client, without installing new services or running resource-intensive computations inside the cluster (MapReduce, Spark or others). Download Jethro.
PERFORMANCE FROM A UNIQUE INDEXING TECHNOLOGY
The key to Jethro’s superior performance on Hadoop is its unique indexing technology. Jethro’s indexes are sorted, multi-hierarchy, compressed bitmaps. They are created automatically for every column, and are written in an efficient, append-only fashion – avoiding expensive random writes and locking. Queries use indexes to read only the data they need, instead of performing full scans, leading to faster response times.
SCALABILITY AND HIGH-AVAILABILITY
Jethro’s nodes are stateless and highly elastic, allowing easy scale-out to meet concurrency requirements. Jethro’s index and column files are stored as standard files on HDFS or Amazon S3 and benefit from their native scalability and high availability.
MINIMAL HADOOP CLUSTER LOAD
Other SQL-on-Hadoop solutions uses a brute force method – each node of the cluster scans and processes its local data for every query. In contrast, Jethro leverages its indexes to surgically fetch only the relevant data for each query, dramatically reducing the load on the shared Hadoop cluster – freeing it for other computations and supporting more concurrent queries.
Full Scan/Brute Force vs. Index Access
Full Scan/Brute Force
all SQL-on-Hadoop solutions
Read entire data set. Every time.
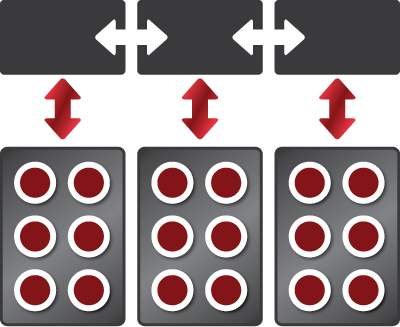
Impact on Hadoop Cluster
Massive # of unnecessary I/O
Huge consumption of CPU and memory
Index Access
Jethro SQL-on-Hadoop Solution
Analyze Indexes. Fetch only relevant data.
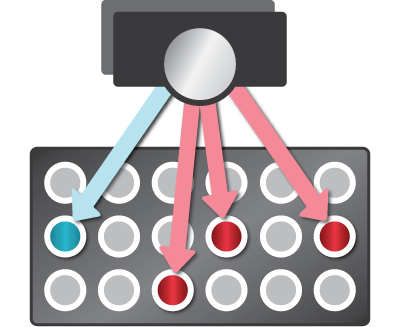
Impact on Hadoop Cluster
Drastically lower Hadoop cluster load
Low I/O, CPU, memory
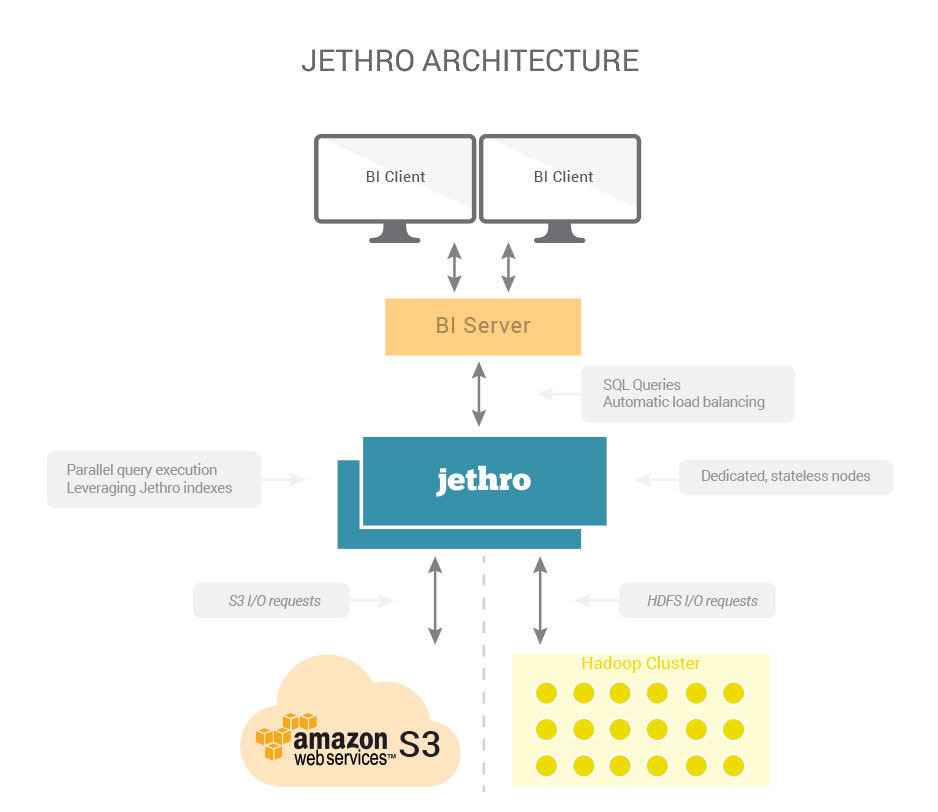
High-Level SQL-on-Hadoop Architecture
SQL INTERFACE
BI tools, such as Tableau, Qlik or Microstrategy connect to Jethro using JDBC or ODBC and issue standard SQL queries. The driver automatically load-balances SQL statement across all Jethro hosts.
QUERY PROCESSING
Jethro runs on one or few dedicated, higher-end hosts optimized for SQL processing – with extra memory and CPU cores, and local SSD for caching. The query hosts are stateless, and new ones can be dynamically added to support additional concurrent users.
STORAGE LAYER
Jethro stores its files (e.g., indexes) in an existing Hadoop cluster or in an Amazon S3 bucket. With Hadoop, it uses a standard HDFS client (libhdfs) and is compatible with all common Hadoop distributions. Jethro only generates a light I/O load on HDFS – offloading SQL processing from Hadoop and enabling sharing the cluster between online users and batch processing.
DATA LOADING & INDEXES
A loader service processes input files and creates query-optimized column and index files, which are encoded, compressed and then stored on HDFS or Amazon S3. This service can run on its own host or on one of the query processing hosts.